
The Transformer model has been very influential in the field of NLP and constitutes the engine of the state-of-the-art LLMs, still powering the ChatGPT engines as of the time of the writing. In the following the architecture of a Transformer is presented, along with a description of each step and a brief explanation of the related mathematical formulae. This section contextualizes our study within the broader scope of NLP progress, but also provides a necessary technical foundation for the analysis and development of further innovations in the generative artificial intelligence (GAI) space.
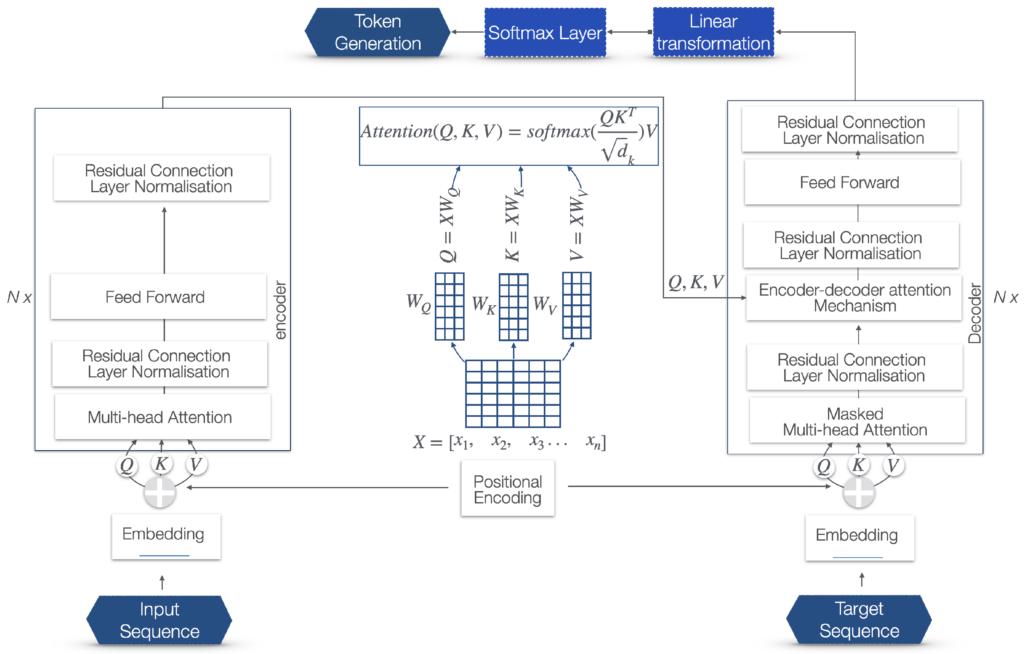
The Transformer model is based on a mechanism, referred to as self-attention, that directly models the relationships between words in a sentence, regardless of their respective positions in the sentence.
Encoder
The left part of the diagram represents the encoder, which processes the input data. The input sequence is processed through multiple layers of multi-head attention and feed-forward networks, with each of these layers followed by the residual connection and linear normalization steps.
Embeddings: The numerical representations of words, phrases, or other types of data. In the case of LLMs, they represent words or tokens. Each word or token is mapped to a vector of real numbers that captures semantic and syntactic information about the word. The words with similar meanings or used in similar contexts will have similar vector representations. Input Sequence Embedding: Input tokens’ conversion into vectors of a fixed dimension.
Positional Encoding: Adds information about the positional order of the respective words of the sequence.
- Q, K, V: The input to the multi-head attention layer is first linearly transformed into three different sets of vectors: queries (Q), keys (K), and values (V). This is done for each attention head using different, learned linear projections.
- Scaled dot-product attention: For each head, the scaled dot-product attention is independently calculated. The dot product is computed between each query and all keys, which results in a score that represents how much focus to place on other parts of the input for each word. These scores are scaled down by the dimensionality of the keys (typically the square root of the key dimension) to stabilize the gradients during training. A softmax function is applied to the scaled scores to obtain the weights on the values.
- Attention output: The softmax weights are then used to create a weighted sum of the value vectors. This results in an output vector for each head that is a combination of the input values, weighted by their relevance to each query.
- Concatenation: The output vectors from all heads are concatenated. Since each head may learn to attend to different features, concatenating them combines the different learned representation subspaces.
- Linear transformation: The concatenated output undergoes a linear transformation to produce the final product of the multi-head attention layer.
- Feed-forward network: A fully connected feed-forward network is applied to each position separately and identically.
- Residual connection and linear normalization: Applies residual connections and layer normalization.
Decoder
The right part of the diagram represents the decoder that generates the output.–Target sequence embedding: Converts target tokens into vectors and shifts them to the right.
- Target sequence embedding: Converts target tokens into vectors and shifts them to the right.
- Masked multi-head attention: Prevents positions from attending to subsequent positions during training.
- Encoder–decoder attention mechanism: Attends to the encoder’s output and the decoder’s input. The keys (K) and values (V) come from the output of the encoder. The similarity between the queries and keys is calculated. This involves taking the dot product of the queries with the keys, scaling it (usually by dividing by the square root of the dimension of the key vectors), and then applying a softmax function to obtain the weights for the values.
- Feed-forward network: Following the attention mechanisms, there is a feed-forward network. It consists of two linear transformations with a ReLU activation in between.
- Residual connection and linear normalization: Applies residual connections and layer normalization.
- Linear transformation before softmax: In the final layer of the decoder, the Transformer model applies a linear transformation to the output of the previous layer. This linear transformation, typically a fully connected neural network layer (often referred to as a dense layer), projects the decoder’s output to a space whose dimensionality is equal to the size of the vocabulary.
- Softmax function: After this linear transformation, a softmax function is applied to these projected values, which creates a probability distribution over the vocabulary based on the positional attributes.
- Token selection: The probability distribution for each potential token is analyzed considering the context of the sequence. This analysis determines which tokens are most likely to be the appropriate next elements in the sequence. The token selection can be done using various strategies like greedy decoding, sampling, or beam search.
- Token generation: Based on this probability distribution, tokens are generated as the output for each position in the sequence.
- Sequence construction: The selected tokens are combined to form the output text sequence. This can involve converting sub-word tokens back into words and dealing with special tokens such as those that represent the start and end of a sentence.
- Post-processing: Post-processing is performed, based on syntactical, grammatical, and language rules.
References
[1]Balogh, E.P.; Miller, B.T.; Ball, J.R. Improving Diagnosis in Health Care; The National Academies Press: Washington, DC, USA, 2015. [Google Scholar]
[2]Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 5998–6008. [Google Scholar]
